No More Dropped Metrics: Reliable Telemetry in Node.js
Node's shutdown is synchronous, and that's not changing any time soon. Plus, adding to the process' event loop would just extend the shutdown indefinitely. It's a good thing node's shutdown works the way it does.
Traditionally, developers have relied on custom shutdown and destroy functions within telemetry libraries to handle this gracefully. However, these approaches often fall short in scenarios where the process is terminated abruptly, such as when a SIGTERM signal is sent from the hosting platform.
In this blog post, we'll explore a novel solution implemented in the recent release of the Node.js Taskless Loader (v0.0.17) that leverages Atomics and Worker Threads to guarantee reliable telemetry data capture and transmission, even in the face of abrupt process terminations.
The Caveats
First, and most importantly, what we're talking about is the Node.js exit event, which cannot be abandoned once started, and must remain synchronous.
Listener functions must only perform synchronous operations. The Node.js process will exit immediately after calling the 'exit' event listeners causing any additional work still queued in the event loop to be abandoned.process.once("exit", function(signal) {
// this fetch operation will be abandoned in-flight
fetch("...").then(function() {});
});Using the code pattern we're discussing anywhere else in the codebase would be a terrible idea; node is at its best when everything is asynchronous and evented. You've been warned. ❤️
The Pitfall of SIGTERM
In a typical setup, libraries attempt to flush pending data and gracefully close connections during the shutdown process, usually by registering a hook into process.onBeforeExit(). However, when a process is terminated abruptly, such as through a SIGTERM signal, these custom shutdown functions may be using the event loop, causing anything in flight to be discarded.
This problem is particularly prevalent in managed environments, like container orchestration platforms, where processes are often terminated gracefully using SIGTERM. As a result, data gets lost, leading to incomplete insights and inaccurate reporting.
Blocking With Atomics
The Atomics namespace contains utilities for operating on or performing atomic operations in both Node and in browsers.
Atomics.storewrites to aSharedArrayBufferwith a new valueAtomics.waitwaits on an index in theSharedArrayBufferto change, blocking the thread until the condition is trueAtomics.notifydeclaratively signals every thread waiting viaAtomic.waitto check for changes in theSharedArrayBuffer
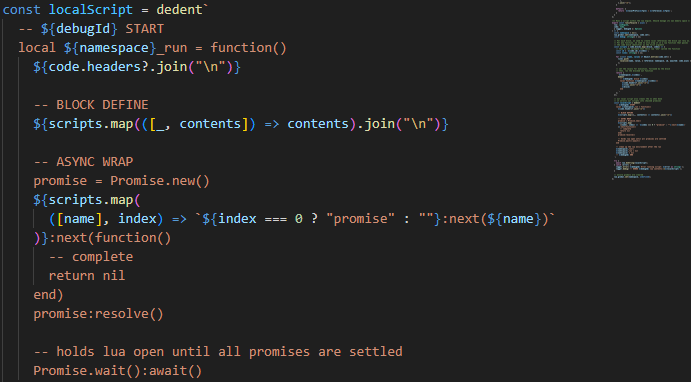
Our general plan is to start our final request inside of a worker thread, and then use Atomics.wait() to block the main thread until the request succeeds or fails. In practice, it looks like this inside of Taskless:
const notifyHandle = new Int32Array(new SharedArrayBuffer(4));
const w = new Worker(localJSCode, {
eval: true,
workerData: {
notifyHandle,
data: { /* url & requestInit... */ },
},
});
Atomics.wait(notifyHandle, 0, 0);
w.terminate();(eval is unsafe, only eval code you 100% control with no user input. seriously)
It's not a lot of code! The worker gets the SharedArrayBuffer, and then we block. We only need a signal (not complex data) passed, so an incredibly small ArrayBuffer of 4 is more than enough.
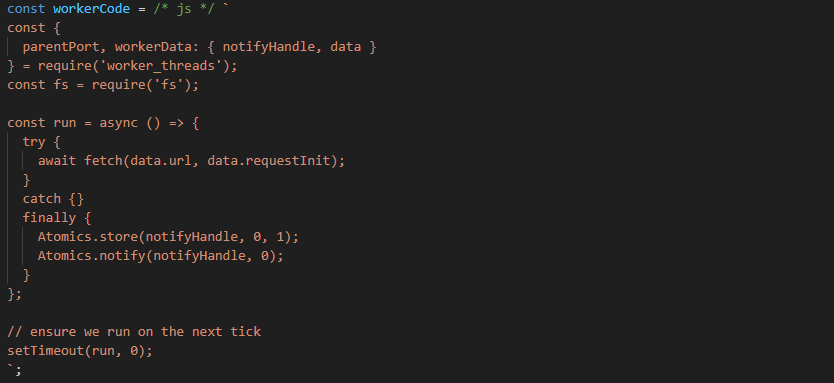
Our "Worker" just unpacks the data which is our arguments for fetch(), makes the request, and then signals the result inside a finally() to ensure it's always called.
const workerCode = /* js */ `
const {
parentPort, workerData: { notifyHandle, data }
} = require('worker_threads');
const run = async () => {
try {
await fetch(data.url, data.requestInit);
}
catch {}
finally {
Atomics.store(notifyHandle, 0, 1);
Atomics.notify(notifyHandle, 0);
}
};
// ensure we run on the next tick
setTimeout(run, 0);
`;A very minimal fetch operation inside a worker thread
The finally is super important. If we never store + notify, then our main thread will never wake up from the blocking operation. We're also not too interested in the contents of our response, only that we attempted it successfully. If we were interested in the result, we could add a MessageChannel to the worker data and send the response via postMessage.
Our empty catch is to ensure any unhandled exceptions from the fetch() call do not crash our worker, falling through to our finally statement.
There's room for improvement, too. The setTimeout exists because our worker code has start on the event loop and Server Sent Events don't work as-coded. While those aren't needed for most telemetry-style events, they may be more valuable in other shutdown scenarios.
The Benefits
The approach implemented in Taskless has significant implications for the broader Node.js ecosystem:
- Guaranteed Data Integrity: By ensuring that all captured telemetry data is reliably sent or logged before the process shuts down, this approach eliminates the risk of losing valuable insights due to abrupt terminations or race conditions. This is especially true when using an asynchronous logging library like pino, where process termination can accidentally remove the cause of termination.
- Seamless Integration with Managed Environments: The use of Atomics and Worker Threads means that regardless of the deployment environment, we can make the final calls required for most APM and logging tools. In managed systems like Kubernetes that use
SIGTERMto end processes, there's now a reliable way to perform the cleanup operations that are increasingly asynchronous. - Improved Accuracy and Insights: Preventing the loss of telemetry data during the shutdown process means a complete picture. For a platform like Taskless, where we tap into your request & response lifecycle, losing information about what we transformed would be considered a process failure.
Generally, we think this is a great approach to the old pattern of await myplatform.pleaseActuallyDrainInTime() on shutdown. We hope more platforms adopt Atomics and workers on shutdown to ensure data integrity through the last call.