What is a Service Mesh?
Service meshes are a battle tested way to deal with the complexity of modern microservices architectures. Done right, they provide a single "hook" where developers can introduce security, observability, and business logic.
What is a Service Mesh?
A service mesh is a dedicated layer that handles service-to-service communication in a microservices architecture. It acts as a transparent proxy, intercepting and controlling network traffic between services. Traditionally, a service mesh consists of a data plane, which comprises a set of lightweight proxies deployed alongside each service, and a control plane that manages and configures these proxies.
For engineers tasked with operational concerns, the service mesh is a consistent place for implementing security features such as mutual TLS and certificate rotation. For application developers, a service mesh offers a range of features focused on L7 (application layer) concerns. These include automatic retries and timeouts, intelligent routing, URL rewriting, and improved observability through detailed metrics, logging, and tracing.
Wait, You Can Just Rewrite Any URL?
Service mesh tools like Envoy, Taskless, and Consul come with the ability to inspect and change every request & response pair. This creates a single insertion point for business logic, without grepping through the codebase to find every invocation of a service or SDK.
- You can implement consistent retry and failover logic across services: Ensuring that services can gracefully handle failures and automatically retry failed requests can be complex and time-consuming, especially since every SDK often has their own opinions on how often (or if at all) retries should occur.
- Handling URL rewriting and routing: In the application code, you may want to only expose a single SDK or API, but behind the scenes you may want to select from a variety of vendors based on market, price, or uptime conditions. To the application, it looks like the same API it always called, but inside the service mesh, it can be swapped transparently with another provider.
- Ensuring observability and monitoring of inter-service communication: Gaining visibility into the health and performance of service-to-service communication is crucial for troubleshooting and optimization. It's even harder to to figure out what's wrong when the service being called isn't one you control. Being able to quickly sample every aspect of the request & response speeds up your incident resolution by letting you quickly replay an inspect the call that failed, not just the error that resulted.
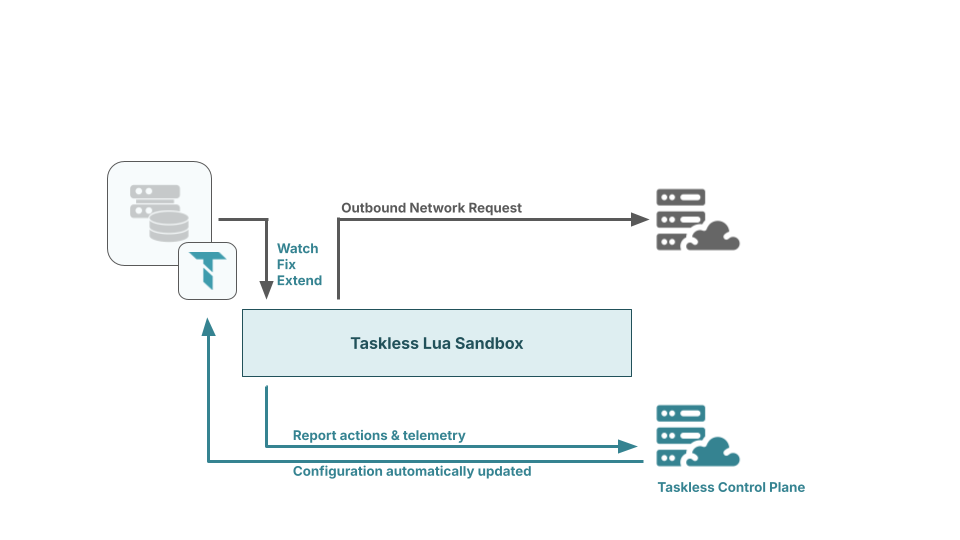
Taskless: A Modern Approach to Service Mesh
Traditionally, the service mesh runs at the container layer, and usually as part of your cloud native configuration. This works well enough when your application developers and cloud team are one-and-the-same, but eventually your site reliability needs are going to grow in a different direction from your application developer's concerns.
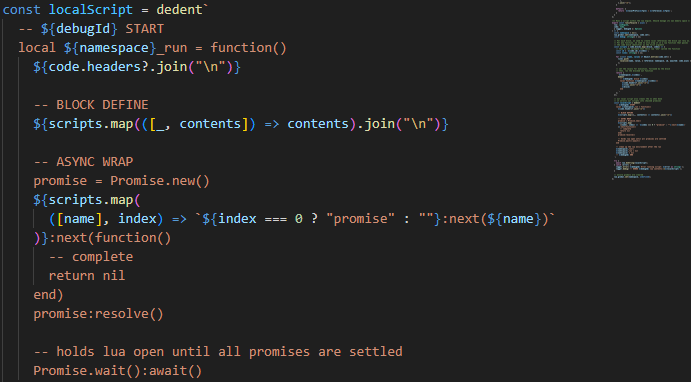
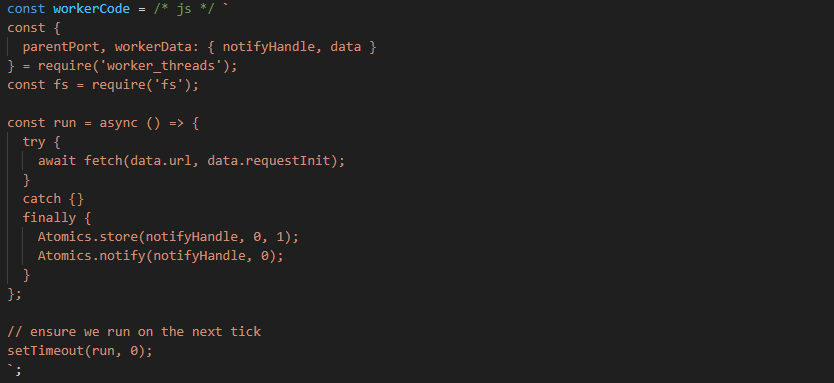
Taskless kept the L7 functionality of a service mesh and moved them up the stack to the application developers. On a technical level, it runs the sidecar in-process, in a sandboxed Lua VM, packed via WebAssembly.
The result is a new kind of service mesh, built for the application developer's concerns, without the steep learning curve and specialized knowledge associated with traditional service meshes.
But Do You Need a Service Mesh?
It's a good question! If you think about a service mesh as just a piece of infrastructure, then the answer is "eventually, maybe."
But if you instead think of a service mesh as a single place where you can manage all of your L7 concerns, regardless of application and language then the answer is more of a "how soon". And answering "when" is a topic so nuanced, it deserves its own post.